AQI分析与预测背景信息AQI指的是空气质量指数,用来衡量一个城市的空气清洁或污染的程度,数值越小则空气质量越好。任务说明哪些城市的空气质量较好 / 较差?【描述性统计分析】空气质量在地理上的分布,是否存在着一定的规律?【描述性统计分析】沿海城市与内陆城市的空气质量是否存在不同?【推断统计分析】空气质量主要受到哪些因素的影响?【相关系数分析】全国空气质量的整体情况是怎样的?【区间估计】怎么来预测一个城市的空气质量?【线性回归】数据集描述现在获取了2015年的空气质量数据集,该数据集包含了全国主要城市的相关数据及空气质量指数,数据情况如下:列名含义City城市名AQI空气质量指数Precipitation降雨量GDP城市生产总值Temperature温度Longitude纬度Latitude经度Altitude海拔高度PopulationDensity人口密度Coastal是否沿海GreenCoverageRate绿化覆盖率Incineration(10000ton)焚烧量(10000吨)最好/最差的5个城市data = pd.read_csv("data.csv")
番茄工作法其实就是一种简单的时间管理方法。具体来说,首先需要明确一个工作任务,设定好番茄时间(一般是25分钟),在这个时间内专注工作,中途不允许做任何与该任务无关的事,直到番茄钟响起,然后在纸上画一个记号,记录下来,然后设定休息时间(一般是五分钟)。from tkinter import * import math ## ---------------------------- CONSTANTS -------------------------- # PINK = "#e2979c" RED = "#e7305b" GREEN = "#9bdeac" YELLOW = "#f7f5dd" FONT_NAME = "Courier" WORK_MIN = 25 SHORT_BREAK_MIN = 5 LONG_BREAK_MIN = 10 reps = 0 timer = None ## ---------------------------- TIMER RESET ------
Excel文件格式姓名部门基本工资提成邮箱刘备首领3000300666@qq.com张飞小兵1000100666@qq.com代码from openpyxl import load_workbook from email.mime.text import MIMEText from email.utils import formataddr from email.header import Header import smtplib ## Excel文件地址 wb = load_workbook('./000.xlsx') sh = wb.active ## 修改自己的SMTP服务器信息 server = smtplib.SMTP_SSL('smtp.qq.com', 465) server.login("666@qq.com", "K0000000iFm") title = '<tr>' for i, row in enumerate(sh.rows): if i == 0: for ceil in r
准备工作打开VS Code插件中心,安装Django插件(Roberth Solís),关闭VS Code。接着安装Django,这一步必不可少,不然无法创建项目。pip install django打开终端,进入某个目录(项目路径),执行命令创建项目:django-admin startproject 项目名称接着为Django项目创建一个虚拟环境cd 项目名称 python -m venv venv至此准备工作告一段落。配置问题打开VS Code,文件-打开文件夹-项目文件夹。同时按下Ctrl+Shift+P搜索找到Python: 解释器后点击,选择含有虚拟环境的Python解释器,选择后可以在左下角看到自己的运行环境,其中虚拟环境有(venv: venv)的标识。因为是虚拟环境,所以之前安装的第三方包都无法使用,需要在虚拟环境中重新安装,包括必备包django。打开VS Code终端,发现终端能用虚拟环境运行了。pip install django接着需要创建VS Code必备的launch.json,点击运行-添加配置-Python-Django。完成后点击运行-启动调试,运行
要从经过动态渲染的网页中爬取数据,需要使用Selenium库打开一个模拟浏览器访问网页,然后获取渲染后的网页源代码。实战中通常和Requests库结合使用,实现优势互补。如果用Requests库能获取到需要的网页源代码,那么优先使用Requests库进行爬取;如果用Requests库获取不到,再使用Selenium库进行爬取。Selenium安装谷歌浏览器首先查看谷歌浏览器的版本号。单击谷歌浏览器右上角的 ⋮ 按钮,在弹出的菜单中执行 帮助 -> 关于Google Chrome,在弹出的页面中查看所安装的谷歌浏览器的版本号。接着下载安装包:官方下载地址:https://chromedriver.chromium.org/downloads镜像下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver找到与自己谷歌浏览器最接近的的版本,下载对应当前操作系统的安装包。注意:Chrome推送新版本更新要小心,因为一不小心点了升级,再运行之前写的程序,就会出现Chrome与chromedriver版本不一致的问题,导
PDF派几十个强大的PDF在线工具,无限次使用,永久免费,没有注册入口,人人都是VIP!PDF可以转Word、Excel、PPTX、图片、Pages、Numbers、Keynote、EPUB、JPG、PNG、TIFF、Mobi(以上格式也可转回PDF)其他好用的免费PDF工具:PDF解锁、拆分PDF、旋转PDF、压缩PDF、加密PDF、添加水印到PDF、PDF页码、提取图片、重新排列PDF、删除PDF页面、图片格式转换。免费的在线图片格式转换工具:PNG转JPG、HEIC转JPG、TIF PNG转、BMP转JPG、JPG转PNG、GIF转PNG。我愿称之为最强!打工人必备网站!网站地址PDF派:https://www.pdfpai.com/类似网站PDF24 Tools:https://tools.pdf24.org/zh/PDF2Go:https://www.pdf2go.com/zhDocFly:https://www.docfly.com/Nero PDF Tools:https://pdf.nero.com/飞扬PDF:https://www.viyoung.net/ONEPD
聚合书库一个在线免费电子书、小说在线阅读网站,聚合书库资源数据所有数据均来自互联网公开数据,想要看什么电子书、小说,直接搜索书名或者作者即可,给广大网友提供最好的小说阅读服务,全站小说电子书免费阅读并且无弹窗,网站界面干净无广告,书架自动追更,免注册,打造全网最全,方便追更及收藏书的工具。网站地址聚合书库:https://mianfei22.com/类似网站书葵网:https://www.shukui.net/24h搜书网:https://24hbook.com/书书读小说:https://www.shushudu.com/Yiove书源仓库:https://shuyuan.yiove.com/
文本函数LEFT/RIGHT:提取左/右侧N个字符MID:从指定位置开始提取特定数目的字符FIND:在一个文本值中查找另一个文本值(区分大小写)REPT:按给定次数重复文本TEXT:设置数字格式并将其转换为文本,例如:TEXT(1,REPT(0,3)) 结果为 001SUBSTITUTE:在文本字符串中用新文本替换旧文本查找和引用函数VLOOKUP:在数组第一列中查找,然后在行之间移动以返回单元格的值参考Excel 函数(按类别列出)
PyMySQL是一个纯Python实现的MySQL客户端库,支持兼容Python 3,用于代替MySQLdb。select查询数据import pymysql # 第一步:建立连接 conn = pymysql.connect( host="192.168.2.0", port=3306, user="test", passwd="", database="test", charset="utf8mb4", ) try: # 第二步:获取游标(字典型游标) with conn.cursor() as cursor: # 第三步:执行SQL,返回受影响行数 sql = "select * from aaa" rows = cursor.execute(sql) print("受影响行数:", rows)
import requests from bs4 import BeautifulSoup import json import os url = "https://book.douban.com/top250" header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"} def getHTML(num): r = requests.get(url, headers=header, params={"start": num}) return r.text ## 定义方法存储一个网页页面数据 def getListData(html): booklist = [] soup = BeautifulSoup(html, &qu
import matplotlib.pyplot as plt import numpy as np # 图片左右翻转 img_arr = plt.imread("1.jpg") img = img_arr[:, ::-1, :] # [行, 列, 颜色] plt.imshow(img) plt.show() # 图片上下翻转 img = img_arr[::-1, :, :] plt.imshow(img) plt.show() # 对颜色翻转:RGB=>BGR img = img_arr[:, :, ::-1] plt.imshow(img) plt.show() # 图片裁剪 img = img_arr[20:100, 20:100, :] plt.imshow(img) plt.show() # axis=1横向拼图,axis=0纵向拼图 img = np.concatenate((img_arr, img_arr, img_arr), axis=1) plt.imshow(img) plt.show()
Excel导入数据到MySQLimport pymysql import openpyxl wb = openpyxl.load_workbook('员工表.xlsx') ws = wb.active params = [] for row_idx in range(2, ws.max_row + 1): values = [] for col_idx in range(1, ws.max_column): values.append(ws.cell(row_idx, col_idx).value) params.append(values) conn = pymysql.connect(host='', port=3306, user='', passwd='', database='', charset='utf8mb4') try: with conn.cursor() as cursor: # 批量插入操作
bisect内置模块,用于维护已排序序列。Bisect是二分法的意思,这里使用二分法来排序,它会将一个元素插入到一个有序列表的合适位置,这使得不需要每次调用sort的方式维护有序列表。在一些情况下,这比反复排序列表或构造一个大的列表再排序的效率更高。以排序顺序插入import bisect lst = [] bisect.insort(lst, 2) bisect.insort(lst, 5) bisect.insort(lst, 3) bisect.insort(lst, 6) bisect.insort(lst, 3) print(lst) # [2, 3, 3, 5, 6]insort()用于按排序顺序将项目插入列表。处理重复bisect模块提供了两种处理重复的方法:可以将新值插入现有值的左侧,也可以插入右侧。insort()函数实际上是insort_right()的别名,它在现有值之后插入一个项目。相应的函数insort_left(),在现有值之前插入。
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn import metrics data = load_iris() iris_target = data.target iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) ## 选择类别为0和1的样本 iris_features_part = iris_features.iloc[:100] iris_target_part = iris_target[:100] ## 将数据集划分为训练集与测试集 x_train, x_test,
已失效!😂就是加速一款油猴脚本,也有提供网页版,完美支持百度网盘文件无限速批量下载,一键批量解析文件,免费无限制白嫖使用,更多功能正在缓慢开发中。脚本仅供学习研究使用,原理是使用公开的中转账号接口进行中转。下载地址就是加速:https://greasyfork.org/zh-CN/scripts/463707网页版:https://api.94speed.com/web/Motrix:https://motrix.app/zh-CN/download
menu.pyclass MenuItem: """Models each Menu Item.""" def __init__(self, name, water, milk, coffee, cost): self.name = name self.cost = cost self.ingredients = { "water": water, "milk": milk, "coffee": coffee } class Menu: """Models the Menu with drinks.""" def __init__(self): self.menu = [ MenuItem(name=&
如果你在浏览器中收藏了很多书签,还想数一数有多少条书签的话,要怎么办呢,难不成要一条一条数吗?当然不是了,一个最简单的办法就是:先导出全部书签为html文件统计html文件中“HREF=”出现的次数即可利用Notepad++的查找功能,可以快速统计出有多少个Notepad++下载地址:https://notepad-plus.en.softonic.comChrome这里以Chrome浏览器为例,点击浏览器右上角的三个竖点 ⋮ -> 书签 -> 书签管理器,接着点击页面右上角的三个竖点 ⋮ -> 导出书签 -> 保存。使用Notepad++打开刚刚保存的html文件,使用快捷键Ctrl+F打开查找页面,「查找目标」输入:HREF=,点击「计数」,即可快速统计出有多少个书签了。
Python中,一切皆对象。每个对象由:标识(identity)、类型(type)、值(value)组成。id(obj)返回对象obj的标识;type(obj)返回对象obj的类型;print(obj)直接打印出对象obj的值。同一运算符:is用来比较id,==用来比较值(本质是调用__eq__())。is运算符比==效率高,在变量和None进行比较时,应使用is。特殊成员在Python类中存在一些特殊方法(一般称之为魔术方法),这些方法都是 __方法__ 格式,这种方法(内置方法)在内部均有特殊含义。__init__初始化方法专门用来定义一个类具有哪些属性的方法。__del__方法对象被从内存中销毁前,会被自动调用。__new__构造方法很少用,但比较重要。使用类名()创建对象时,Python解释器首先调用__new__方法为对象分配空间。__new__是由object基类提供的内置静态方法,主要作用有2个:在内存中为对象分配空间返回对象的引用class Foo(object): def __init__(self, name): print("第二
对于普通变量,使用蛇形命名法,比如 max_value对于常量,采用全大写字母,使用下划线连接,比如 MAX_VALUE如果变量标记为“仅内部使用”,为其增加下划线前缀,比如 _local_var当名字与 Python 关键字冲突时,在变量末尾追加下划线,比如 class_类名应该使用驼峰风格(FooClass)函数应该使用蛇形风格(bar_function)安装autopep8autopep8是一种自动格式化Python代码以符合PEP 8编码规范的插件。pip install autopep8 -i https://mirrors.aliyun.com/pypi/simple/
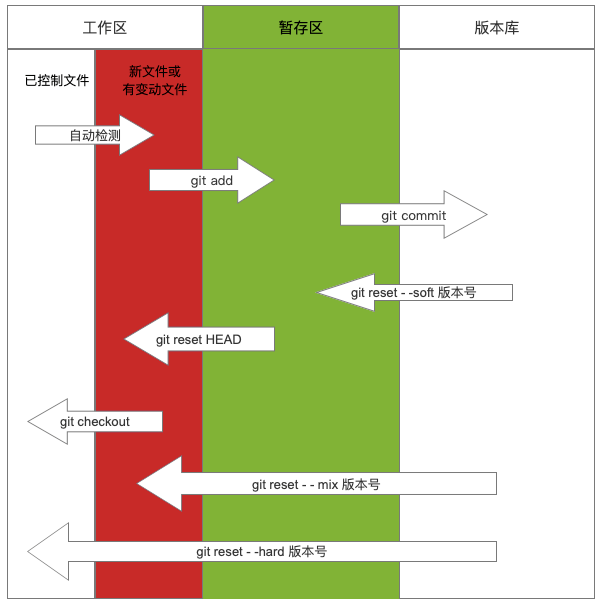
Git的作用是版本控制,即管理文件夹。下载GitGit官网下载地址:https://git-scm.com/downloads本地管理步骤# 1 进入要管理的文件夹,进行本地初始化 git init # 查看当前文件状态(新增和修改过的文件都是红色) git status # 2 添加一个或多个文件到暂存区 git add [file1] [file2] # 添加指定目录到暂存区 git add [dir] # 添加当前目录下的所有文件到暂存区 git add . # 将文件移出暂存区 git rm --cached [file1] # 配置个人信息:用户名、邮箱(可选) git config --global user.name '李小龙' git config --global user.email '1@qq.com' # 3 生成版本 git commit -m "描述信息" # 查看版本记录 git log # 版本记录图形展示(h是哈希值,s是提交记录) git log --graph --pretty=format:"%h %s&
网上各种找首先,肯定是找一下有没有别人写好的库,自己写不现实的。最终找到了 js-xlsx,评价还不错,不过已经好久没有更新了,将就用用看咯。js-xlsx 虽然支持修改导出文件的样式,不过是在它的专业版中,其分为社区版和专业版,社区版是开源的,但是却不支持修改导出文件的样式,专业版拥有更多的功能,这其中就包括修改样式。如果需要使用专业版,要邮件联系开发者,去咨询价格,购买它。好在又找到了 xlsx-style 这个项目(同样的好久没有更新了,凑合着用),它可以对导出的 excel 文件进行一些样式上的修改。开干<script src="js/xlsx.extendscript.js"></script> <script src="js/xlsx-style/xlsx.full.min.js"></script> <script src="js/export.js"></script> <script> function btn_expo
三毛
头发渐少,仅剩三根